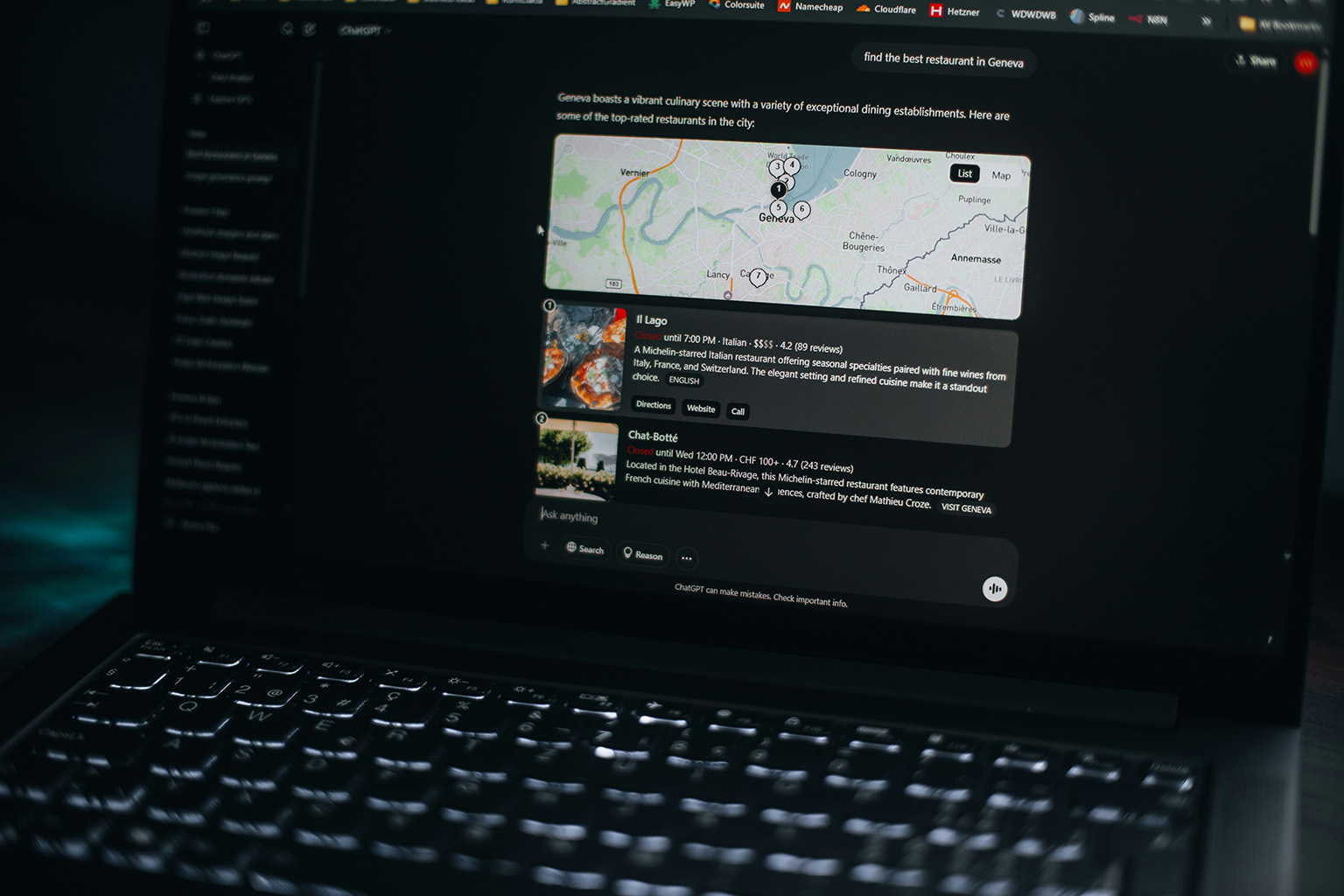

In a recent interview with Roberto Serra, John Campbell, Head of Innovation and AI, unpacks what actually works – from influencing how AI represents your brand, to maintaining organic authority and capturing high-value traffic.
As more searches are resolved directly within AI-generated answers, brands face a simple risk: being left out entirely.
So what actually works?
“More and more searches are now resolved directly within AI-generated answers, without users ever visiting websites: what should a brand concretely do to avoid disappearing and actually influence those answers?”
Brands need to focus on three key areas. First, building strong content on their own website, this is what LLMs draw from directly, giving the brand influence over generated answers and the opportunity to earn citation links. Second, ensuring that third-party websites being referenced by LLMs, such as news outlets, review sites, and blogs, mention the brand in a positive and accurate way. Third, maintaining an active presence on social platforms, since LLMs increasingly pull from social content too, so it’s far better to have your own accounts and content being picked up than to leave that space to others.
“Many are chasing “tricks” to get cited by AI, but without technical structure, structured data, and real authority, brands don’t even enter the LLM radar: in your experience, what clearly differentiates a brand that gets selected by AI from one that gets ignored?”
The brands that get selected by AI are the ones that have a strong, established association to the products or services they offer. This isn’t new, it’s always been the case. When people think about vacuum cleaners, they think of Dyson, Shark, or Henry Hoover. That association has been built over years of marketing, from above-the-line campaigns to digital. LLMs are simply a reflection of that. So while fixing technical aspects and implementing structured data is important, fundamentally the brands that get recommended are the ones with that deep product association already in place. If that association is weaker than your competitors’, you might be able to over-index on LLM-specific tactics in the short term but in the long run, that alone won’t be enough.
“There’s a lot of talk about “being present in AI answers,” but few connect that visibility to real business outcomes: how should companies actually measure the impact on revenue?”
There are three main groups of KPIs to track.
- The first is visibility / citations metrics from an AI tracking tool, such as share of voice or citation rate. This is important, but it comes with caveats given the non-deterministic nature of LLMs, meaning results can vary between queries.
- The second is website traffic arriving via AI citations, these are the trackable clicks from cited sources. There is however a harder-to-track behaviour, where a user discovers a brand through ChatGPT and then searches for it directly on Google, making attribution genuinely difficult.
- The third is conversion attribution, for B2B, this means adding “How did you find us? Via ChatGPT” as an option on lead forms (getting your sales people to ask this). For ecommerce, it means analysing sessions originating from AI sources across first-click, last-click, and multi-touch attribution models.
“A brand’s presence in LLM-generated answers is often described in terms of “share of voice”: how can this be truly monitored, and what signals show that a brand is gaining ground over competitors?”
Share of voice is a useful metric, but it needs to be tracked alongside others, such as clicks and conversions attributed to AI search, rather than in isolation. One important nuance to consider is the relationship between the number of competitors in your space and how many competitors LLMs tend to recommend. For example, if there are ten main players in a category and ChatGPT typically recommends five, the key question is simply: are you in that five? But this is also where share of voice as a metric starts to break down. If there are only five companies offering a particular service and ChatGPT tends to recommend five, your visibility will naturally look strong but that doesn’t tell you much. In those cases, you need to look beyond raw inclusion and focus on position within the answer and the sentiment around how your brand is described. So share of voice has to be interpreted carefully, always in the context of how competitive your category is and how many brands LLMs typically surface within it.
“The market is full of promises about how to “get into ChatGPT”: what are the most serious mistakes you see companies making when they chase these shortcuts?”
A couple of mistakes stand out.
- The first is the obsession with LLMS.txt files. Until any of the major models formally confirm they are actively using them, there’s limited value in prioritising them (yes easy to make and no harm to have). The logic doesn’t quite hold up either, the idea that models would rely on individual website owners creating a specific file, when they could simply crawl a well-structured website directly, seems technically backward. If the information is already there on the site, the crawler will find it. Think how hard its been for Google to get people to create robots.txt files and Sitemaps. Why encourage that effort to create a separate file.
- The second mistake is the over-use of listicle-style articles on your own website, particularly the kind where you list yourself as number one with heavily favourable commentary about your own brand versus competitors. There are documented cases of this backfiring. As Google actively works to demote this type of content, its influence on LLMs will likely follow. That said, comparison content can work well in specific contexts, particularly when comparing your product against one close competitor, where there isn’t much between you, and the goal is genuinely to help the customer make an informed decision. In those cases, the key is being fair and grounding the comparison in features and facts rather than opinion.
“With ads entering chatbot experiences, the line between answer and promotion is becoming blurred: how much could this affect user trust and brand credibility over time?”
We’re already seeing this used as a differentiator. Anthropic has positioned Claude’s ad-free experience as a direct contrast to ChatGPT’s direction. From a trust perspective, the impact could be significant. People tend to share far more personal and sensitive information with AI assistants than they ever did with a search engine. So when ads start appearing, or when users begin to suspect their conversations are being used to profile them for advertising purposes, the erosion of trust is likely to hit harder than it ever did with Google Search, which always felt more transactional and less personal.
The one mitigating factor worth noting is that the users who will actually see the ads are likely to be those on free tiers, people who are arguably less invested in the platform and perhaps more accustomed to ad-supported experiences. Whether that limits the broader trust damage remains to be seen, but it’s an interesting dynamic to watch as it plays out.
“Advertising inside ChatGPT guarantees visibility as long as you pay, but leaves no lasting value: in your experience, when does it actually make sense to invest in ads, and when does it just become an expensive dependency?”
It’s still early to say definitively how impactful these ads will be, but the right mental model for now is probably to treat them as a display channel, broad reach, brand awareness, getting your message in front of a large audience. Targeting precision will likely be limited, and control over which prompts or users your ads appear against will be minimal, at least initially.
There’s also a structural limitation worth flagging for B2B marketers specifically: if your target audience consists of professionals using AI tools seriously, they’re most likely on paid accounts which means they won’t see ads at all. So for B2B, the channel may simply not reach the right people.
More broadly, brands are already acutely aware of the risks of over-dependence on Google Ads, and that lesson is shaping how they approach new platforms. Few will want to build another expensive dependency from scratch. If anything, that anxiety is accelerating the push towards organic GEO visibility, earning a place in AI-generated answers through genuine authority and content quality, rather than paying for placement that disappears the moment the budget stops.
“Data shows that when a site loses visibility on Google, it quickly loses presence in LLM citations as well: in your experience, have you observed this effect, and what early signals indicate it’s happening?”
Yes, we’ve observed this directly.
Across clients, when we’ve plotted average citation scores against average traditional rankings on Google and Bing, the correlation is strong. Rank well organically, and your citation scores tend to follow.
The nuance, however, is in how the signals surface. When a Google algorithm update hits, you see it immediately across your entire keyword set in Search Console. But LLM visibility tracking is typically based on a much smaller set of prompts, perhaps a few dozen, and while those prompts are related to organic rankings, they’re not identical. So the same correlation doesn’t always show up clearly, particularly if your prompt tracking set is too narrow.
What we have observed, though, is that citation scores can drop for reasons entirely unrelated to Google and this points to a new category of risk. For one client, we saw a significant drop in citation scores when Perplexity changed how many URLs it was willing to surface per result. That client had regularly been appearing with six or seven URLs per prompt. When Perplexity reduced that number, their citation score dropped sharply nothing to do with their content or their Google rankings, purely a platform-level decision. This is something brands need to prepare for: LLM-specific algorithm changes that operate independently of traditional search, and which can materially affect visibility without any warning.
“When a brand doesn’t clearly control its own narrative, AI tends to fill the gaps using third-party sources, often unreliable ones: what can a company do to prevent this kind of “alternative narrative”?”
There are a few approaches here.
- The first is ensuring your own website has comprehensive, accurate content because information vacuums get filled by others. People turn to Reddit and similar platforms to ask questions precisely because they can’t find the answer on an official website. Someone else then answers, and that answer may well be inaccurate. If it gets traction, it becomes part of the narrative that LLMs eventually absorb. Getting ahead of that with authoritative first-party content is the most direct defence.
- The second is about affiliates, and it’s an underappreciated one. If a brand doesn’t have an affiliate programme, third-party publishers and review sites have little to no incentive to include them in their recommendations they won’t send traffic to a brand they can’t monetise. This means those sources, which LLMs frequently cite, will simply leave you out of the conversation. So affiliate strategy is no longer just about driving direct conversions. It’s now also a lever for influencing which sources mention you, how they describe you, and ultimately whether you appear in AI-generated answers at all.
“Language models can absorb and repeat false or defamatory content while presenting it as trustworthy: how real is the risk of reputational attacks through Negative GEO today, and how can they be identified early?”
This is a genuinely difficult one. On the detection side, there are tools that can help, fact-checking layers that take an LLM’s answer about your brand and verify the claims within it. This can help flag and prioritise prompts where inaccuracies are appearing, giving you a clearer picture of where the narrative is drifting.
But it comes back to content again. If models are looking for information about your brand and not finding it on your own properties, you can’t really blame them for pulling from whatever is available elsewhere. The defence is the same, own the narrative proactively with accurate, comprehensive first-party content.
The harder truth is around prompts that are actively seeking out negatives: “what are the downsides of product X” or “what are the complaints about brand Y.” There’s limited you can do to suppress that, because the model is specifically looking for criticism. The most honest answer is: don’t have a bad product. That’s easy to say, but in practice, product and operational improvements take time. In the interim, the best approach is ensuring that any legitimate criticism is outweighed by a far larger volume of accurate, authoritative, positive content so that even when a model looks for negatives, it’s working against a strong foundation.
“Traffic from LLMs is still small in volume but tends to convert much more than other channels: in your experience, what makes these users so ready to take action?”
This is something I was discussing today. A few things are likely contributing to this.
- First, users invest more effort in crafting their prompts than they ever did in typing a search query. That extra effort creates a sense of ownership over the result, there’s almost a satisfaction in having asked the right question and been pointed somewhere relevant. That mindset carries into the session and likely influences how engaged and ready to act they are when they arrive.
- Second, and perhaps more fundamentally, LLMs may simply be doing a better job of matching users to what they actually need. The old behaviour of opening the top three organic results, scanning each one, going back and refining the search, LLMs compress or eliminate that entirely. By the time a user clicks through to a website, a lot of the discovery and filtering has already happened. They arrive further along in the decision-making process.
- Third, and this is harder to measure right now, is the role of memory and personalisation settings. If LLMs are drawing on a user’s history and preferences to shape their recommendations, that would go a long way to explaining why the resulting traffic is so well-matched. We don’t yet have full visibility into how much this is happening or how consistently, but if it’s being applied well, it’s a meaningful part of the story.
“YouTube, Reddit, and experience-driven sources are becoming increasingly central in LLM responses: from this perspective, how is SEO work changing for brands that want to capture high-value traffic?”
On the YouTube side, it’s bringing SEOs much closer to the actual video production process. The brief is increasingly search-driven, this video is being made because it addresses a specific query that appears in traditional search and is also being picked up by LLMs. That’s a shift from how YouTube has historically been treated by brands, which was primarily as a brand awareness or product showcase channel. The intent behind content creation is changing.
On the Reddit side, there’s a real risk of SEOs doing what SEOs sometimes do, finding a channel that’s working and gradually ruining it. If teams start seeding Reddit threads with brand-friendly content designed to influence LLMs, the community will notice, the quality will drop, and the whole signal will degrade. The smarter approach is to treat Reddit as an observation tool rather than a distribution channel. Listen to the conversations happening in relevant communities, understand the genuine questions being asked, and then go and answer those questions through content on your own website. Let Reddit inform your content strategy rather than become a place you try to manipulate. Hint… sign up for reddit pro and use Reddit Answers.
For a smaller subset of brands that already have an established subreddit, there’s a legitimate role to play but it should sit closer to community management and customer service than to content influence. The moment it becomes obviously engineered, it stops working. SEOs have a habit of finding good things and over-optimising them into irrelevance, this is one area where restraint will matter.
Key Takeaways
- “To influence AI-generated responses, brands must prioritise first-party content that is accurate, comprehensive, and structured.”
- “A strong presence on third-party websites and social platforms helps control how AI portrays your brand.”
- “Technical structure matters, but deep product association and long-term authority are what make brands consistently cited by AI.”
- “Measure impact with a mix of visibility, traffic, and conversion metrics rather than relying on any single KPI.”
- “Avoid shortcuts like over-engineered listicles or LLMS.txt files — they can harm credibility and visibility.”
- “AI-driven traffic is highly intent-driven and converts at higher rates, but it requires a foundation of trust and authoritative content.”
Brands that approach AI visibility strategically, combining GEO/SEO best practices with high-quality, authentic content, are the ones most likely to thrive as AI continues to reshape how audiences discover and engage with information.