
In preparation for our Future of Search event at the start of April we’ve been running several tests, building tools, and just generally poking around ChatGPT Search. One of the growing trends on LinkedIn and other social networks is the showing of referral traffic coming to your site via ChatGPT. Many charts show a month-on-month increase which is impressive.
In our research its a mixed bag, some are seeing growing traffic, others not. Its more to do with the industry rather than you GEO efforts ;-).
This places a greater emphasis on ChatGPT and other platforms as a new channel as a source of traffic.
In the grand scheme however, this traffic source is very small in comparison to Google, but it is growing.
That being said, referral traffic only tells you one side of the story, it doesn’t track the users who discover your brand via ChatGPT and then separately search for you. Similarly, referral traffic doesn’t show those users who discover your website mentioned in a result but do not click the link, or do click but are not tracked because they have rejected cookies. There is no “ChatGPT Search Console” that allows you to see the following:
- Impression of when your website is mentioned.
- Which pages that GPT has visited?
- Which pages are index for training purposes by OpenAI?
Until this information is made available (it may never), ROAST have identified a solution for now. With all workarounds and piecing dates together, there are going to be some caveats, but some data is better than none. Server logs are the key.
Server logs have been used for years for several reasons. In the SEO world they are used to track the frequency of Google indexing to your site or flag other crawling problems. This same information can be used for ChatGPT. First of all, let’s dive a little deeper into ChatGPT’s three different bots.
GPTBot
GPTBotis OpenAI’s web crawler, used to index publicly available web pages to improve AI models like ChatGPT..171.207.221 weareroastdevs.wpenginepowered.com – [11/Mar/2025:18:33:28 +0000] “GET /careers/paid-media-account-manager/ HTTP/1.0” 429 162 “-” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)”
ChatGPT-User
This bot represents a human user accessing ChatGPT via OpenAI’s interface, helping to differentiate it from automated bots.23.98.179.16 weareroastdevs.wpenginepowered.com – [06/Mar/2025:03:25:07 +0000] “GET /news/what-bid-strategy-should-i-use-for-paid-search/ HTTP/1.0” 200 343737 “-” “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot”
OAI-SearchBot
OpenAI’s search-focused bot, designed to fetch and process web content for AI-powered search and information retrieval.51.8.102.39 weareroastdevs.wpenginepowered.com – [06/Mar/2025:05:45:09 +0000] “GET /news/the-ultimate-guide-to-googles-new-partner-status-requirements/ HTTP/1.0” 200 317577 “-” “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot”
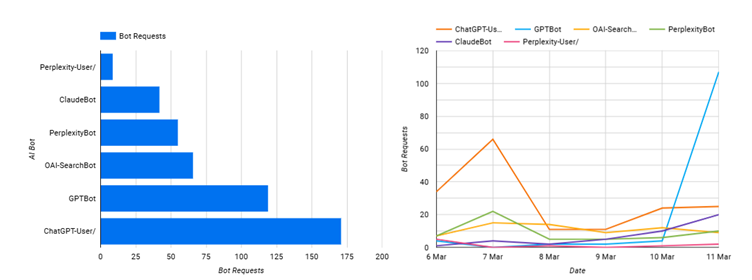
GPTBot
Are you being added to the corpus for training?
The GPTBot will visit your site infrequently, however, you want it to be visiting as many pages as possible so that when future models are trained, your content will be going into the model.
Therefore, overtime you can track as each of your pages gets indexed, ideally you have your log files history for the past few years, and you’ll see what’s covered.
In the example of the ROAST site over the past week we can see that the following have been accessed / crawled. E.g. I have 898 pages / images etc in my site, what % of them has GPTBot crawled – around 1% so far (We only started this process since the 12th the real number will be much higher if we had the back dated log files – we don’t).
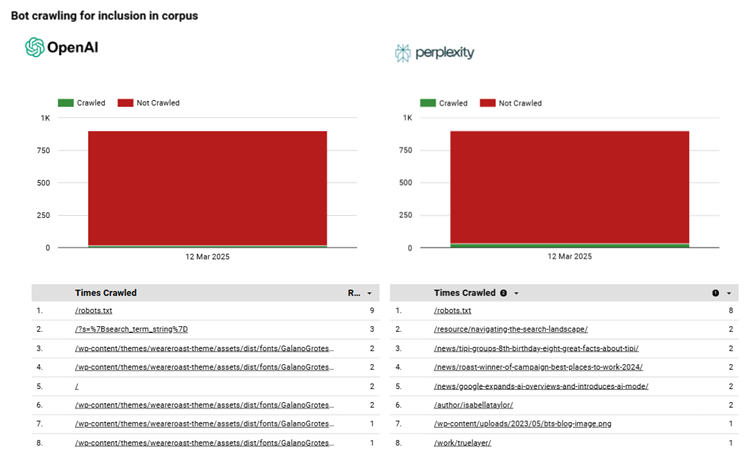
ChatGPT-User
Here’s where it gets interesting.
Go to ChatGPT and ask a question where it used search, and it shows URLs.
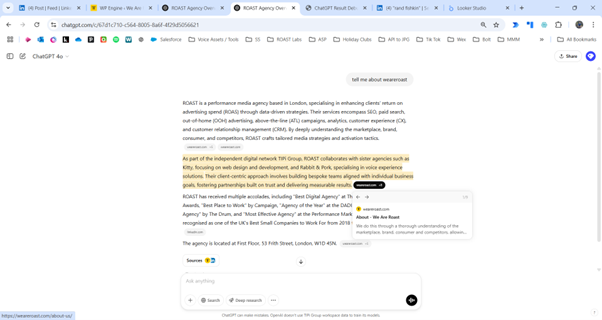
We have an internal tool which debugs the results and shows us the URLS.
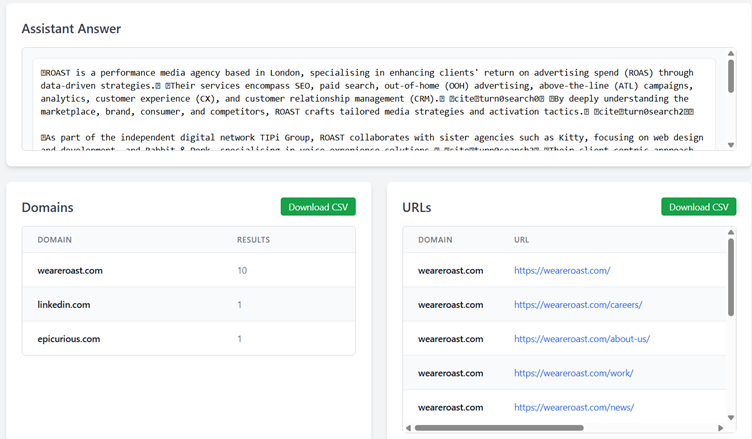
In this example there was 12 URLS, 10 from our site – one even about Roast Chicken…
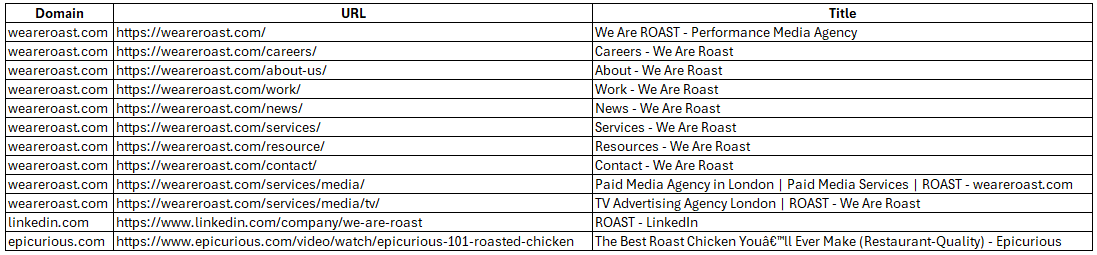
At the same time, ChatGPT-User will come to those pages, we go to the log file we can see.

Yes, it’s the same ten URLs that were seen in the results.
So, from this we can now start to understand.
- Which URLs are used in the search process to augment the result that ChatGPT is creating.
- You could use these visits from ChatGPT-User as a proxy for impressions on ChatGPT.
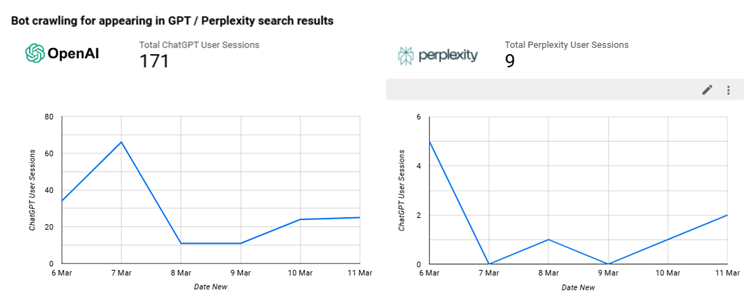
As mentioned, there are some caveats here. There were 10 visits from ChatGPT-User, but that was just one user.
- You could have a script that group these e.g., any visits from ChatGPT-User in quick succession are grouped as one.
- The negative of this would be if more than user on ChatGPT are conducting a search about your brand.
With this data you can now:
- Know which pages are often appearing in ChatGPT searches – therefore make changes to these pages.
- Which ones are not appearing in search which contain useful content.
- In the future these pages should be taken into consideration in migration projects or content audits.
If you’re interested in tracking this information and learning more about how top optimise for AI search get in touch with the team at ROAST Labs.
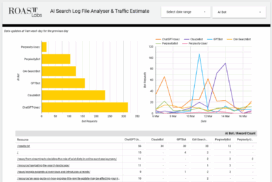
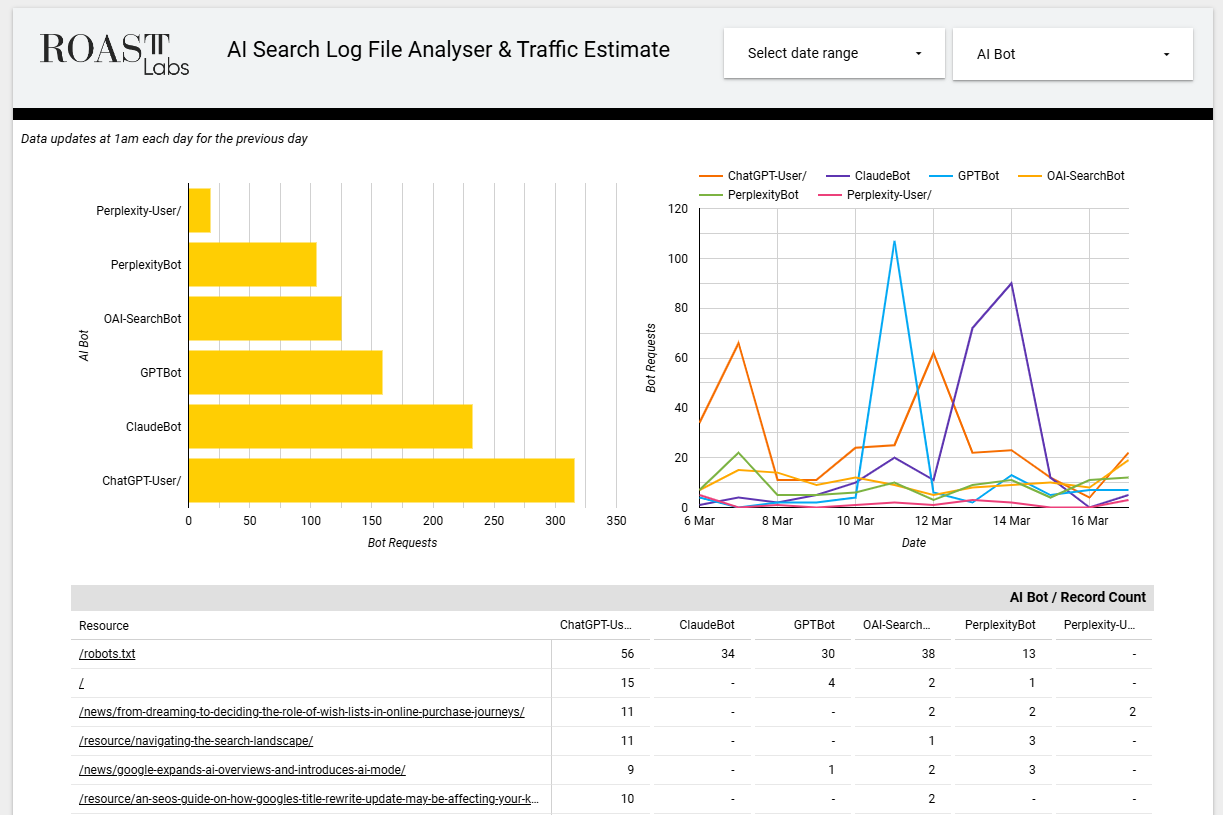
Free looker report template
Below is a free looker report template which currently has real data from the ROAST website.
This uses an Google Sheets App Script which is pulling our log data, parsing and adding to the charts each day.